

Você confia cegamente no modelo de linguagem que utiliza? Com o lançamento frenético de novas inteligências artificiais, como o Llama 3 da Meta ou as atualizações do Gemini do Google, ficamos bombardeados por tabelas de benchmarks técnicos — MMLU, raciocínio matemático, geração de código. Mas, na prática, como saber qual “cérebro” digital realmente raciocina melhor?
A verdade é que, diante de bilhões de parâmetros, a maioria de nós apenas chuta. Fazemos algumas perguntas aleatórias e decidimos qual IA parece mais “esperta”. Esse método empírico é falho, subjetivo e perigoso para quem depende dessas ferramentas para decisões estratégicas ou desenvolvimento de software. A falta de um teste prático de lógica pura nos deixa navegando no escuro.
Para resolver isso, saímos da teoria e fomos para o campo de batalha definitivo da estratégia: o Xadrez. Colocamos o ChatGPT (GPT-4o) para enfrentar o Gemini Pro em um match de 20 partidas. Não foi apenas um jogo; foi um teste de estresse de alucinação, consistência e capacidade de planejamento. O resultado? Um verdadeiro massacre que expôs as entranhas de como esses modelos “pensam”.
Por Que Xadrez é o Teste de QI Definitivo para IAs?
Antes de revelarmos o placar humilhante, é preciso entender por que escolhemos o xadrez e não apenas mais um teste de perguntas e respostas.
Modelos de Linguagem (LLMs) são treinados com grandes volumes de dados da internet. Isso inclui a Wikipédia, o GitHub e, crucialmente, milhões de partidas de xadrez registradas em notação PGN (Portable Game Notation).
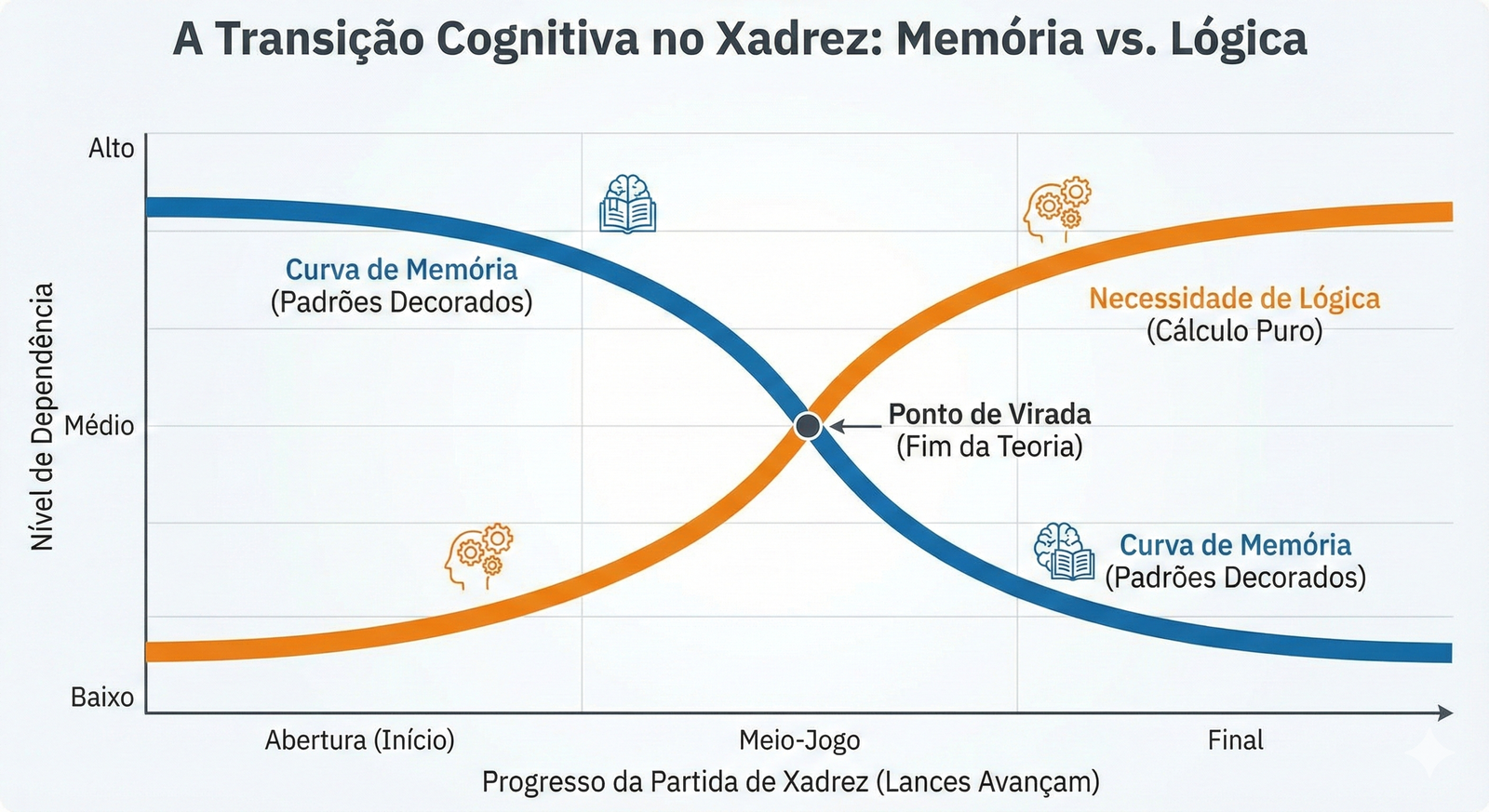
Memória vs. Raciocínio Real
O xadrez nos permite dividir a performance da IA em duas fases distintas:
- Abertura (Memória): Os primeiros 5 a 10 lances geralmente são teóricos (como a Defesa Siciliana). A IA não está “pensando”; ela está recuperando um padrão decorado de seu treinamento. É como um papagaio repetindo uma frase complexa.
- Meio-Jogo (Lógica Pura): À medida que a partida avança, as combinações se tornam únicas. A IA chega a uma posição que nunca existiu exatamente daquela forma em seu banco de dados.
É aqui que a mágica acontece. Quando a memória acaba, o modelo precisa calcular. É nesse momento que separamos a inteligência real da simples probabilidade estatística.
A Engenharia por Trás do Torneio: LLMs e Python
Para realizar este experimento de forma justa, não bastava pedir para eles jogarem no chat. Precisávamos de um ambiente controlado. Desenvolvemos um script em Python utilizando a biblioteca python-chess para gerenciar as regras e garantir que o tabuleiro fosse respeitado.
O Desafio da Estocasticidade
Diferente de um software tradicional, que segue algoritmos determinísticos (se A, então B), os modelos de linguagem são estocásticos — ou seja, aleatórios. Você pode pedir a mesma coisa duas vezes e obter respostas diferentes.
No xadrez, isso é um problema. As IAs tendem a “alucinar” lances ilegais, como mover um Bispo como se fosse uma Torre.
A Solução: O Modelo “Juiz”
Para contornar isso, criamos uma arquitetura com um agente intermediário. O fluxo funcionava assim:
- O Prompt: Instruímos o ChatGPT e o Gemini com uma temperatura baixa (0.1) para serem “Grandes Mestres”, analisarem o histórico PGN e o tabuleiro atual.
- A Jogada: A IA sugere um movimento e uma explicação lógica.
- O Juiz: Um algoritmo verifica se o lance é válido dentro das regras do xadrez.
- Se válido: A peça move.
- Se inválido: O juiz devolve o erro para a IA, mostra o tabuleiro novamente e lista as opções legais, forçando-a a escolher uma jogada possível.
Isso nos permitiu ver não apenas quem joga melhor, mas quem entende melhor as regras e a realidade do jogo.
A Análise do Massacre: Alucinações e “Cheque-Mates” Imaginários
O que observamos durante as partidas foi fascinante e, por vezes, cômico. As diferenças na capacidade cognitiva dos dois modelos ficaram evidentes nas explicações que eles davam para seus movimentos.
O Fenômeno da Confiança Errada
Em nossa experiência rodando esses modelos, o Gemini demonstrou uma tendência alarmante à alucinação convicta.
Em uma das partidas, jogando de brancas, o Gemini fez um lance absurdo e explicou: “Joguei E4 para preparar o avanço do peão para E4”. Ou seja, ele justificou a ação com a própria ação, um raciocínio circular que não faz sentido lógico.
Pior ainda foi quando o Gemini declarou, com total confiança: “Dama toma F7, Xeque-Mate”. Na realidade, não era mate. O Rei preto podia simplesmente se mover. O modelo “imaginou” uma vitória, encerrou seu raciocínio lógico e começou a jogar peças aleatoriamente, perdendo a Dama e a partida logo em seguida.
A Precisão do ChatGPT
Por outro lado, o ChatGPT (GPT-4o), embora não seja um motor de xadrez dedicado como o Stockfish, mostrou uma consistência muito superior.
- Ele reconheceu aberturas complexas.
- Cometeu muito menos lances ilegais.
- Identificou corretamente sequências de mate que o Gemini deixou passar.
Enquanto o Gemini lutava para entender onde suas peças estavam, o ChatGPT estava montando táticas de médio prazo.
O Placar Final: 17,5 a 2,5
Após 20 partidas disputadas, alternando quem jogava com as peças brancas e pretas para eliminar a vantagem do primeiro movimento, o resultado foi incontestável.
- ChatGPT de Pretas: 9 Vitórias, 1 Derrota.
- ChatGPT de Brancas: 8 Vitórias, 1 Derrota, 1 Empate.
Resultado Consolidado:
ChatGPT: 17,5 pontos Gemini: 2,5 pontos

O Que Isso Significa para Seus Projetos?
Este teste vai muito além do xadrez. Ele é um proxy para a capacidade de lógica sequencial e aderência a instruções.
Se o Gemini alucina a posição de uma peça em um tabuleiro de 64 casas (um ambiente com regras finitas e perfeitas), qual a confiança que podemos ter nele para tarefas complexas de lógica de programação ou análise jurídica, onde as regras são mais subjetivas?
Os dados mostram que, para tarefas que exigem precisão lógica e menor taxa de alucinação, o modelo da OpenAI ainda sustenta uma liderança técnica significativa sobre o concorrente do Google neste cenário específico.
Conclusão: Dominando a Tecnologia por Trás da IA
A inteligência artificial não é mágica; é código, estatística e probabilidade. O experimento do xadrez prova que, ao manipularmos os prompts e as configurações (como a temperatura), podemos extrair resultados incrivelmente diferentes, mas as limitações intrínsecas de cada modelo permanecem.
Saber integrar esses modelos via API, criar agentes juízes para corrigir erros e estruturar o pensamento da máquina é a habilidade mais valiosa do mercado atual. Não basta usar o chat; é preciso saber construir com ele.
Se você quer deixar de ser apenas um usuário de ferramentas e passar a ser o criador que desenvolve soluções inteligentes, o caminho é dominar a linguagem que conecta tudo isso.
Pronto para programar o futuro?
Você não precisa ser um gênio da matemática para criar aplicações como esta. Na trilha de Aplicações IA com Python da Asimov Academy, nós guiamos você do zero absoluto até a construção de projetos complexos, ensinando a lógica e o código necessários para dominar o mercado.
[Conheça a Asimov Academy e comece sua jornada na Programação com IA hoje mesmo]